
I’ve always been fascinated with the concepts of Artificial Intelligence, and automation. Especially since my entire adult life I’ve worked as an Engineer in factories and manufacturing settings. As machine learning technologies develop and progress, we are going to be seeing more and more applications for AI powered automation into more creative fields, such as content generation and image/art generation. So I thought it would be fun to see how much of a Youtube video on a given subject could be automated, or facilitated with machine learning, artificial intelligence and Python.
OpenAI offers cheap access to their Davinci language model and their GPT3 image generation model (https://beta.openai.com/docs/introduction) via their API. I wanted to pick a topic I am not an expert at, and since the day I was working on this was the day of the FIFA world cup, I thought that’d be a great choice for a test topic.
I used the DaVinci language model to facilitate the production of a script. Since the responses are limited, and the tool is not meant for long broad answers, I asked the DaVinci model a series of questions: “What is the World Cup” , “What is FIFA”, “When is the World Cup”, “How is the World Cup organized”, “Where is the World Cup”, “What the winners of the World Cup receive” and so forth. Once I removed the prompts I had asked it, I had a bout 700 words for a quick video essay of a few minutes.
Having a script, I ran it through a NLTK Natural language processing (NLP) which took the script, broke it down into sentences and placed them in a Python list, that I could iterate a loop over.
(Note, there is a small cost associated with these AI services, see OpenAI’s website for info, but it’s pretty cheap).
Using OpenAI’s API, I set up a for loop for each line in my Python list of sentences from the script that the DaVince Language model produced. The loop would feed the OpenAI image generation model one sentence at a time, and save the image that is generated. In the end, I would end up with about 30 images for my video, one for each sentence in the list generated from the script. Each image at 1024×1024 for the OpenAI image generating neural network cost about 1.5 cents (or $0.015) so 30 images at the largest resolution cost me less than a USD.
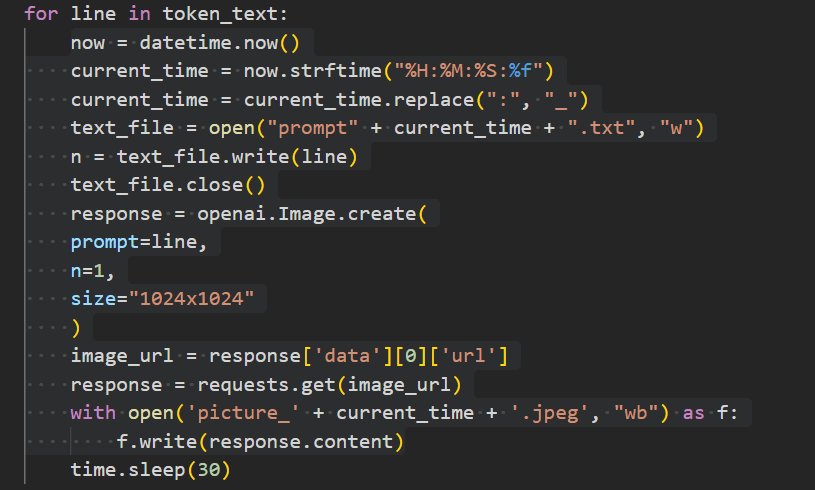
So now I had a script mostly generated by DaVinci (Did do some clean up and streamlining to make sure it flowed) and a series of images for my video essay on the FIFA world cup.
Next I used Google’s Text To Speech (TTS) service to generate a voice over with the script, and now I had about a 3 min audio file based on the script.
Loading up Premiere Pro, I cleaned up the audio since there were inconsistent pauses at paragraphs, set the narration to my generated images. The images mostly lined up with the prompt that was used to generate it in the video. Exported, and voila! I had a 3 min and change video that was mostly generated by algorithms or Artificial learning.
In conclusion, using AI and machine learning are very powerful tools to streamline the creation of content, correcting errors and speeding up portions of the workflow, saving people tons of time. Having said that, human review and touch is still needed, otherwise the content will lack that je ne sais quoi and authenticity that most people like from their small content creators. The images were hit or miss, but always interesting in trying to see how the model got trained, and what I generates based on the input.
I think most creators will have to face the options of eventually using some of these tools and techniques, or face being left behind with time. But the human element will always be needed so that the content is not sterile and lifeless.
Link for the “FIFA World Cup (AI generated)” video: https://youtu.be/lhHPOU33uQI
